內容分享前…
其實含辛茹苦撰寫與上傳這些內容,除了希望可以幫助到更多有心要經營網站的朋友外,無非也希望能找到更多需要 awoo 協助與並肩作戰的好夥伴!!所以若需要下載又剛好想要評估 SEO公司的服務與報價時,就請將網址、網站核心商品或服務關鍵字以及相關聯絡方式,寄到ada@awoo.com.tw 吧!!而我們會盡快免費協助分析建議與報價的。
最後就在此也期待看到想用心經營網站的您與拼命專注於SEO的 awoo 相遇後的火花嘍!!

由於今天的主題就是看 Google 從 Florida Update 開始、可以觀察到哪些 SEO 相關的蛛絲馬跡。
所以當然在一開始、我們就先來談談何謂 Google更新…
Google 為了針對每筆搜尋查詢提供最相關的結果,密切地觀察每日數百萬名訪客的使用模式。
根據紀錄資料分析這些搜尋模式之後,Google的工程師得以更新搜尋演算法,改善搜尋結果顯示順序..
而當時 Google 搜尋機制主要會有三個階段。
首先搜尋引擎 Spider 會開始抓取全球網路上網站資訊,
接著搜尋引擎就會根據這些資料進行解析(包括標題內容、連結結構)並建立索引。
最後就是當消費者在搜尋引擎輸入某一些關鍵字時,搜尋引擎就會透過演算法開始進行一些篩選與解析,再回傳用戶可能會需要的搜尋結果。

早期的 Google 更新
就是指上述第二個階段的更新,
因為早期搜尋引擎技術還不夠,所以需要進行索引階段的更新,
而這更新在當時也叫做 Google Dance。
(包括每年 Google 所舉辦的盛大舞會…)
不過到了 2003 年 5 月後,Google Dance 就成為歷史名詞了,
因為那個時候就不是索引資料的更新、而是已經可以做到每日的更新了…
那現在…就讓我們從 80 年代開始聊起吧…

在這動盪的 80 年代末期,也就是 1979 年時,蒂姆·柏納-李爵士 Sir Tim Berners-Lee 發明了 World Wide Web.

90年代的google更新
1990-Archie(by Alan Emtage)
當時若要找什麼學術期刊就會需要 Archie,
雖然這看起來似乎還滿偉大的,只不過需要完全一模一樣的文字與標題才能找到。
所以事實上還並不是那麼的完善。
1993-Veronica(by Students of University of Nevada )
1993-WWW Wanderer(Matthew Gray)
而這一年、世界上出現了第一隻 www 的 Spider 就叫 WWW Wanderer..
1994-WebCrawler(Brian Pinkerton)
此為當時最先進的搜尋引擎,且在去年僅能抓到網址,這個時候已經可以抓到網頁中的內容了。
1995-Lycos(Michael Mauldin of CMU)
開發了名為 “狼蛛” 這個搜尋引擎,也是全球第一個會出現搜尋引擎結果敘述的搜尋引擎。
(補充:狼蛛是主動找獵物與搜尋引擎一樣..)
1996-Alta Vista(Louis Monier of DEC)
這是當時最多人使用的搜尋引擎,
只是當初這搜尋引擎只是為了證明 DEC 的電腦跑很快,
故當時這搜尋引擎其實是不被重視的,後來這位開發者就跑去 EBAY 了!!

不過那是個 搜尋引擎最佳化 不受重視的年代。
根據我們的分析與判斷、發現最根本的原因應該是,
當時所用的技術是用關鍵字與網頁內容相關度來做排名,
(故很可能找到事實上沒有任何關係的網站..)
加上搜尋技術上又沒有重大創新與突破,容易作弊且又沒有任何營利模式。
(當時最紅的營利模式就是 Yahoo! 這樣的入口網站..)
故就算有這麼一個劃時代的新技術、但仍是乏人問津…
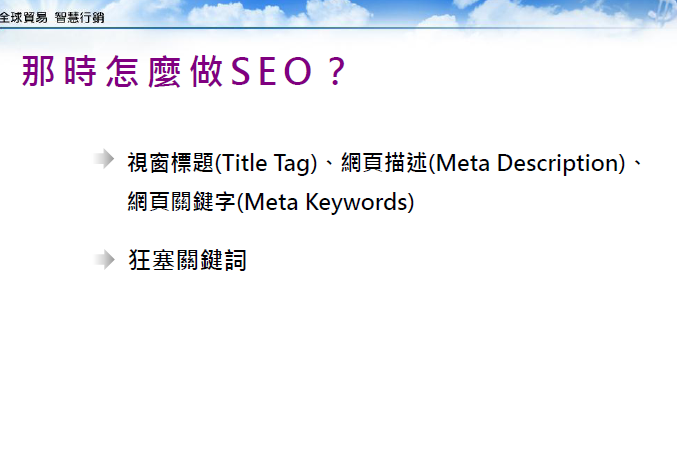
那在這樣一個年代又要怎麼做 SEO優化 ?
簡單說就是視窗標題(Title Tag)、網頁描述(Meta Description)、
網頁關鍵字(Meta Keywords)以及狂塞關鍵詞就可以了!!

但在這個時候…出現了一位 Larry Page…
且 Larry Page 從小看過 Nikola Tsala 的傳記後就發表了以下言論…
I wanted to invent things,but I also wanted to change the world.“(Larry Page)
發願不只要有所創新,且還決定要取得商業上的成功。

且還在進入史丹佛博士班前還認識了 Sergey Brin 並開啟了 Google 的扉頁。

至於 Terry Winograd 是一位互動設計大師且為 Larry Page 當時的專題指導教授。
而這專題 “BankRub” 主要就是在研究誰連結了你的網頁可能會很有用(反向連結 Bank Link)!!

此時也如方才 Larry Page 的傳記感想所提到的,
“這件事在實務上能有什麼應用呢??”
後來最後就決定,不如來做這個如何..“如何決定一個網頁的排名和權威性?

而這技術也參考了學術論文的排名方法…
引用(Citation)和註解(Annotation)
所謂引用就是指某人 “引用” 了某位大師的言論,
而註解就是指在引用後某人又提出了一些 “意見或評論” 。
且這引用的人又是不是一位有身分地位的人等..
但..
這個反向連結與正確性又要怎麼計算出來呢??
就這麼剛好…當時 Larry Page 有一位不太一樣的朋友…

佩吉排序(Page Rank)
(繞口令時間)
一個網頁的重要性,取決於它有多少個網頁連結,以及連結它的網頁又有多少個網頁連結。
這個計算公式就是計算有多少網頁反向連結 “數量” 以決定網頁權威度與排名。

也在這個時候就發表了搜尋研究史上被引用最多的論文
The Anatomy of a Large-Scale Hypertextual Web Search Engine

後來 Page Rank 就真的紅了!!
查詢獨立(Query-Independent)就是事先先將網站 PR 值計算出來,與用戶的搜尋是各自獨立的。
(如此也可以增加效能)
且這樣的有多少反向連結的計算還真的是比較準。
也對於 Spam 免疫(至少一開始是這樣啦…),
而這與早期只要塞關鍵字的做法來的準確許多,最重要的是不久的將來、在商業上取得了絕對的成功。

雖然從此開啟了搜尋世代…
但人性永遠有貪婪和墮落的一面,便很自然的產生了眾多 SPAM…
此時也很多人開始試圖操作 SPAM 影響 Page Rank 的準確性。
到了 2003 年,雖然網路上甚至很多言論聲稱 “Page Rank 已死??”
(旁白)你會發現到,Google的重大更新,往往跟處理SPAM問題有關,Google 怎麼處理SPAM問題呢?
讓我們繼續看下去…
Written by 蔡先生
![Read more about the article 2016 台灣成長駭客年會 [精彩回顧] 跨越美國與台灣的人性派成長駭客-貝克菜](https://isearch.awoo.com.tw/wp-content/uploads/2016/12/unnamed-file-300x300.jpg)
![Read more about the article 用數據建立廣告投資成功方程式 [ iCHEF資廚管理顧問行銷長 程開佑 ]](https://isearch.awoo.com.tw/wp-content/uploads/2014/11/iCHEF-300x266.png)
